1. Intro
데이터 중심 애플리케이션 설계 3장을 읽으면서 가장 이해하기 어렵고 헷갈렸던 것이 SS 테이블과 LSM 트리의 개념적 차이였다.
둘다 세그먼트 병합과 컴팩션을 수행하는것은 동일해보이는데… LSM 트리가 알고리즘이라는 얘기도 책에 서술되어있고, 동시에 저장소 엔진이라는 개념도 서술되어있어서, 정확히 LSM 트리가 자료구조인지? 알고리즘인지? 데이터 저장소 엔진인지? 그럼 SS 테이블과의 연관관계는 무엇인지?가 상당히 이해하기 어려웠다.
책을 여러번 읽었으나, 차이점을 발견하지 못해 처음에는 거의 동일한 개념이라고 결론내릴려 했으나, 요새 핫한 ChatGPT에 혹시나 질문을 했더니 차이가 있다는 내용에 크게 맨탈 붕괴가 왔다. 특히 LSM 트리는 빠른 읽기와 쓰기를 보장해준다고 하는데, SS 테이블이 임의의 쓰기와 정렬된 읽기를 보장해주는 자료구조라는 관점에서 읽기와 쓰기가 동일하게 빠른것이 아닌가? 왜 LSM 트리만의 장점인거지? 라는 생각이 들었다.
•
ChatGPT와의 질문 및 답변

나뿐만 아니라, 책 스터디를 함께 하는 Matthew도 동일하게 헤매고 있었고 둘다 개념을 이해하고 내재화하는데 어려워 추가적으로 많은 내용을 조사하게 되었고 결국 어느정도 정리를 할 수 있었다.
최종적인 정리된 내용은 다음과 같다.
2. SS 테이블 (Sorted String Table)
2.1. 정의
•
키로 정렬된 자료구조(Sorted String Table)
•
로그 구조화 저장소 세그먼트 내 저장된 키-값 쌍을 키로 정렬한 것
2.2. 특징
•
세그먼트 병합과 컴팩션
◦
세그먼트 병합과 컴팩션을 백그라운드 스레드에서 수행
◦
데이터 자체는 정렬된 형태로 세그먼트 파일로 저장되어있음 (디스크, HDD)

•
디스크에 저장된 데이터를 찾기 위한 인메모리 색인이 존재
◦
정렬된 데이터이므로 모든 키의 색인을 유지할 필요 없음
◦
희소 색인(sparse index)의 형태로 구성 가능

•
불변성의 특성을 띔
◦
한번 입력된 키-값 데이터는 수정되지 않음
◦
이로 인해 중복된 키가 존재 가능 → 공간 낭비 → 세그먼트 병합(Merge)를 통해 최적화 진행
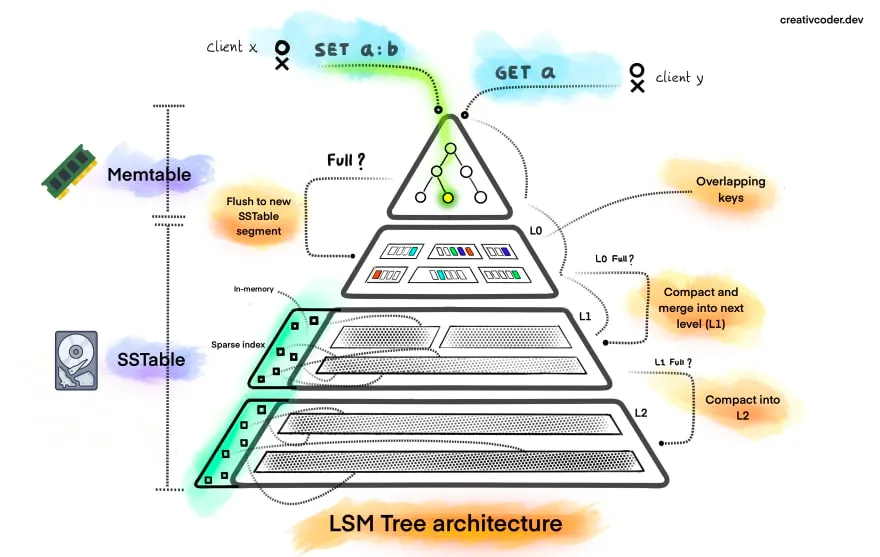
3. LSM 트리 (Log-Structured Merge-Tree)
3.1. 정의
•
SS 테이블을 확장/응용한 자료구조
•
Patrick O'Neil 이 작성한 논문에 따르면 다음과 같이 표현을 할 수 있음

낮은 비용으로 색인을 제공하며 고성능의 데이터 삽입과 삭제를 지원하는 디스크 기반의 자료구조
a disk-based data structure designed to provide low-cost indexing for a file experiencing a high rate of record inserts (and deletes) over an extended period
3.2. 특징
•
주요 특징
◦
정렬된 파일 병합과 컴팩션 원리를 기반으로 함
◦
백그라운드에서 연쇄적으로 SS 테이블을 지속적으로 병합함
◦
데이터가 정렬된 순서로 저장되어 있음 → 범위 질의에 효율적
◦
디스크 쓰기가 순차적이기 때문에 높은 쓰기 처리량 보장 가능
◦
메모리(C0 Tree)와 디스크(C1 Tree) 두가지 컴포넌트(트리)로 구성되어있음
•
컴포넌트
◦
메모리
▪
멤테이블(memtable) 이라고 부름
▪
balanced tree 데이터 구조를 띔
•
예) 레드 블랙 트리, AVL 트리
◦
디스크
▪
SS Table
▪
SS 테이블의 형태로 데이터가 구성되어있음
3.3. 알고리즘
•
데이터 쓰기 (삽입, Write)
1.
멤테이블에 우선 데이터를 저장함. 이때 B-Tree의 형태이므로 데이터는 이미 정렬이 되어있음
2.
사용자가 설정한 멤테이블의 Threshold를 넘어서면 데이터를 새로운 SS Table 파일(디스크)에 flush 진행
•
멤테이블이 이미 정렬된 key, value를 유지하고 있기 때문에 빠른 쓰기 (Fast Write)가 가능
•
새로운 SS 테이블은 가장 최근 세그먼트가 됨
•
디스크에 Flush를 하는동안 새로운 쓰기는 새로운 멤테이블 인스턴스로 진행
•
데이터 읽기 (Read)
1.
멤테이블에서 데이터 조회
2.
멤테이블에 데이터가 없는 경우 최근에 생성된 세그먼트 순서대로 데이터 조회
a.
키가 존재하지 않을 경우 가장 오래된 세그먼트까지 조회 필요
b.
비효율적인 접근을 최적화 하기 위해 블룸 필터 사용
•
데이터 병합 (Merge At SS Table)
◦
백그라운드 스레드에서 세그먼트 병합과 컴팩션을 통해 새롭게 정렬된 SS 테이블 (세그먼트)를 생성
◦
세그먼트 병합과 컴팩션을 통해 중복된 데이터를 제거하여 디스크의 크기를 적정 수준으로 유지
3.4. SS 테이블 압축 및 병합 전략
•
크기 계층 컴팩션 (Size-Tiered Compaction)
◦
상대적으로 좀 더 새롭고 작은 SS 테이블을 상대적으로 오래됐고 큰 테이블에 연이어 병합
•
레벨 컴팩션 (Level Compaction)
◦
키 범위를 더 작은 SS 테이블로 나누고, 오래된 데이터는 개별 “레벨”로 이동
◦
컴팩션을 점진적으로 진행하여 디스크 공간 사용 최적화
4. 결론
•
SS 테이블은 key-value 쌍의 데이터 구조에서 key가 정렬된 데이터 구조를 의미한다.
•
LSM 트리는 SS 테이블의 자료구조를 활용한 자료구조이다.
◦
LSM 트리의 디스크 컴포넌트가 SS 테이블로 구성되어있다.
•
둘다 세그먼트 병합과 컴팩션 원리를 기반으로 한다.