내용 정리
1. Intro
1.1. 파티셔닝의 정의
•
샤딩
◦
데이터 셋이 매우 크거나 질의 처리량이 매우 높을 경우, 데이터를 파티션으로 쪼개는 작업
1.2. 확장성
•
파티셔닝의 주된 이유 = 확장성
•
비공유 클러스터에 다른 파티션을 다른 노드에 저장할 수 있음
•
대용량 데이터 셋을 여러 디스크에 분산 시킬 수 있으며 질의 부하를 여러 프로세스에 분산
•
각 노드에 자신의 파티션에 해당하는 질의를 독립적으로 실행할 수 있음
•
노드를 추가해서 질의 처리량 증가
•
여러 노드에서 병렬 실행 가능
1.3. 파티셔닝과 복제
•
복제와 파티셔닝을 함께 적용해서 각 파티션의 복사본을 여러 노드에 저장
•
각 레코드는 정확히 한 파티션에 속하더라도 여러 노드에 저장해서 내결함성 보장 가능
•
한노드에 여러 파티션에 저장 가능
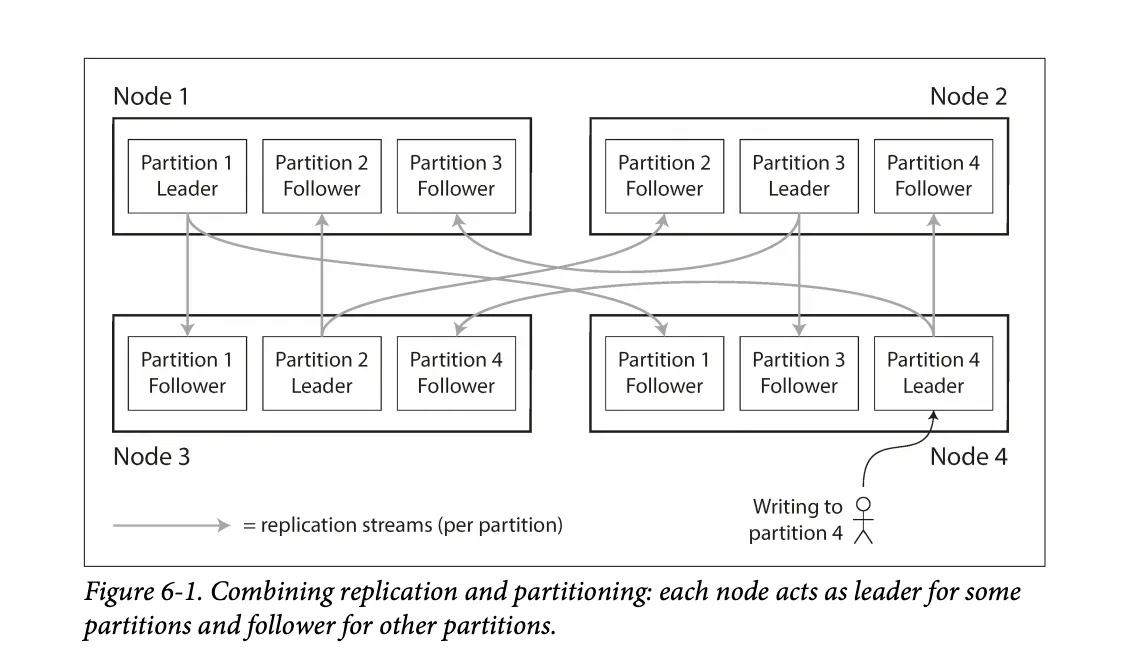
•
리더 팔로워 복제 모델과 파티셔닝 예시
2. 키-값 데이터 파티셔닝

파티셔닝의 목적?
- 데이터와 질의 부하를 노드 사이에 고르게 분산시키는 것
•
핫스팟
◦
불균형하게 부하가 높은 파티션
•
파티셔닝이 고르게 이루어지지 않아 다른 파티션 보다 데이터가 많거나 질의를 많이 받는 파티션이 있는 경우 쏠렸다(skewed)라고 함
•
키-값 데이터 모델의 파티셔닝 종류
◦
키 범위 기준 파티셔닝
◦
키 해시값 기준 파티셔닝
2.1. 키 범위 기준 파티셔닝
•
정의
◦
각 파티션에 연속된 범위 (어떤 최소값~최대값)의 키를 할당하는 것
•
특징
◦
키 범위 크기가 반드시 동일할 필요 없음 (데이터가 고르게 분포하지 않을 수도 있음)
◦
파티션 내 키를 정렬된 순서로 저장 가능 (SS 테이블과 LSM 트리)
▪
범위 스캔 용이
▪
키를 연쇄된 색인으로 간주해 질의 하나로 관련된 레코드 여러개 읽을 수 있는데 활용 가능
•
단점
◦
핫스팟을 유발 할 수 있음
•
파티션 경계 설정 방법
◦
관리자 수동 선택
◦
데이터베이스 자동 선택
2.2. 키 해시값 기준 파티셔닝
•
정의
◦
쏠림과 핫스팟의 위험을 방지하기 위해 키의 파티션 결정 시 해시 함수를 사용하는 파티셔닝
•
특징
◦
해시 함수를 이용해 각 파티션에 해시값 범위를 할당하고, 파티션의 범위에 속하는 모든 키를 파티션에 할당
◦
일관성 해싱 (해시 파티셔닝)
▪
CDN 등 인터넷 규모의 캐시 시스템에서 균등하게 분산시키는 방법
▪
중앙 제어나 분산 합의가 필요하지 않도록 파티션 경계를 무작위로 선택
▪
데이터베이스에서는 실제로 잘 동작하지 않아 현실에서는 거의 쓰이지 않음
•
단점
◦
효율적인 범위 질의 불가
▪
인접 키들이 파티션마다 분산되어 정렬 순서가 유지되지 않음
•
예시

•
cf) 카산드라
◦
키 범위 / 키 해시값 기준 파티셔닝 전략을 섞어서 사용
◦
테이블 선언 시 여러 컬럼을 포함하는 복합 기본키 지정
▪
키의 첫부분(복합키의 첫번째 컬럼): 해싱 적용 → 파티션 결정
▪
남은 컬럼: 카산드라 SS 테이블에서 데이터를 정렬하는 연속된 색인으로 사용
▪
복합키의 첫번째 컬럼은 값 범위 검색 질의 불가하나 나머지 컬럼은 범위 스캔 가능
2.3. 쏠린 작업 부하와 핫스팟 완화
•
항상 동일한 키를 읽고 쓰는 극단적인 상황에서는 모든 요청이 동일한 파티션에 몰릴 수 있음
◦
예) 인플루언서의 SNS 사이트. 동일한 ID 해시값 사용
•
현대 데이터 시스템은 대부분 크게 쏠린 작업부하를 자동으로 보정 못함
•
애플리케이션 레벨에서 쏠림 완화 필요
◦
예) 매우 많이 쏠리는 키 발견 → 키의 시작/끝에 임의의 숫자를 붙이는 것
•
다른 키에 쪼개서 쓸 경우, 읽기 실행에 추가적인 작업 필요
•
모든 것은 Trade Off
3. 파티셔닝과 보조 색인
•
앞서 설명한 파티셔닝 방식은 키-값 데이터 모델에 의존
◦
기본키에만 적용 가능
•
보조 색인은..?
◦
파티션에 깔끔하게 대응 안되는 문제 있음
•
보조 색인이 있는 데이터베이스 파티셔싱 방법
◦
문서 기반 파티셔닝
◦
용어 기반 파티셔닝
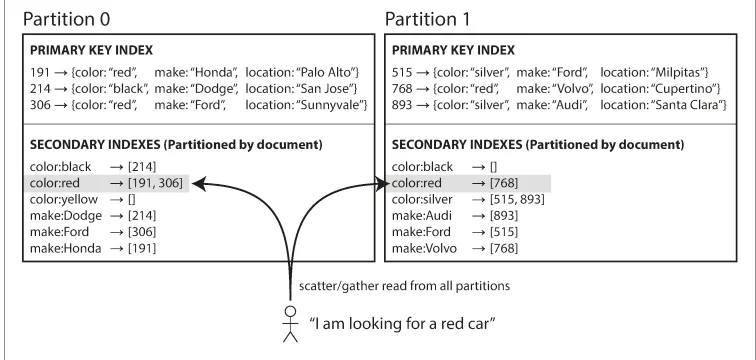
3.1. 문서 기반 보조 색인 파티셔닝
•
정의
◦
보조 색인이 추가될 경우, 데이터베이스 파티션은 자동으로 색인 항목에 해당하는 고유 ID 목록에 추가
•
특징
◦
다른 파티션에 어떤 데이터가 저장되었는지 신경쓰지 않음
◦
문서 ID에 포함된 파티션만 다룸
◦
지역 색인 (local Index)
•
스캐터/개더 (scatter/gather)
◦
파티셔닝된 데이터베이스에 특정 질의를 날려 모든 파티션에 질의를 보내 얻은 결과를 모아 질의를 보내는 방법
◦
보조 색인을 이용한 질의는 큰 비용이 될 수 있음
◦
여러 파티션에 질의를 병렬 실행하더라도 스캐터/개더는 꼬리 지연 시간 증폭을 발생 시킬 수 있음
•
예시
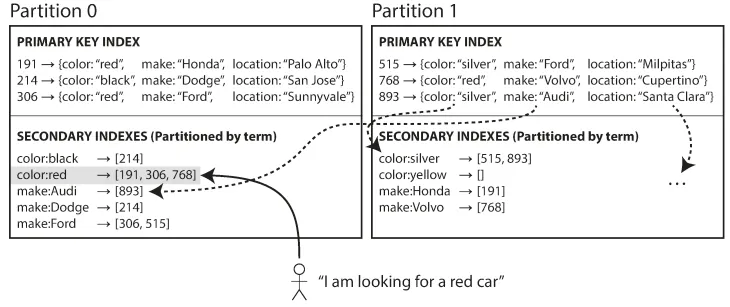
3.2. 용어 기준 보조 색인 파티셔닝
•
정의
◦
찾고자 하는 용어에 따라 색인의 파티션을 결정하는 방식의 색인 (term-partitioned)
◦
용어: 문서에 등장하는 모든 단어를 의미
•
특징
◦
전역 색인
▪
모든 파티션의 데이터를 담당
◦
파티셔닝 시, 용어자체를 쓰거나, 용어의 해시값 사용 가능
◦
문서 파티셔닝 색인에 비해 읽기가 효율적
◦
쓰기가 느리고 복잡함
▪
단일 문서에 쓸 때 해당 색인의 여러 파티션에 영향을 줄 수 있음
•
사용처
◦
리악 - 검색 기능
◦
오라클 - 데이터 웨어하우스
•
예시
◦
color:red
▪
a~r : 파티션 0에 저장
▪
s~z: 파티션 1에 저장
4. 파티션 재균형화 (rebalancing)
•
재균형화(rebalancing)란?
◦
클러스터에서 한 노드가 담당하던 부하를 다른 노드로 옮기는 과정
•
리밸런싱 기대 효과/요구사항
◦
부하(데이터 저장소, 읽기 쓰기 요청)가 클러스터 내 노드 사이에 균등 분배
◦
리밸런싱 중 읽기 쓰기 요청 이상 없음
◦
리밸런싱이 빨리 실행되고, 디스크 I/O 부하를 최소화 할 수 있도록 노드들 사이에 필요 이상으로 데이터가 옮겨져서는 안됨
•
리밸런싱 전략 종류
◦
파티션 개수 고정
◦
동작 파티셔닝
◦
노드 비례 파티셔닝
4.1. [리밸런싱 전략 1] 해시 값에 모드 N 연산 실행 (쓰면 안되는 방법)
•
모드(mod) 연산을 활용하여 리밸런싱 진행
◦
hash(key) mod 10 → 0~9 사이 숫자 반환
◦
노드가 10대? 0~9 숫자를 각각 배정하여 각 키를 노드에 할ㄹ당
•
문제점
◦
노드 개수 N 변경 시, 대부분의 모든 키가 노드 사이에 옮겨져야 함
◦
리밸런싱 비용이 매우 큼
◦
데이터를 필요 이상으로 이동 시킴
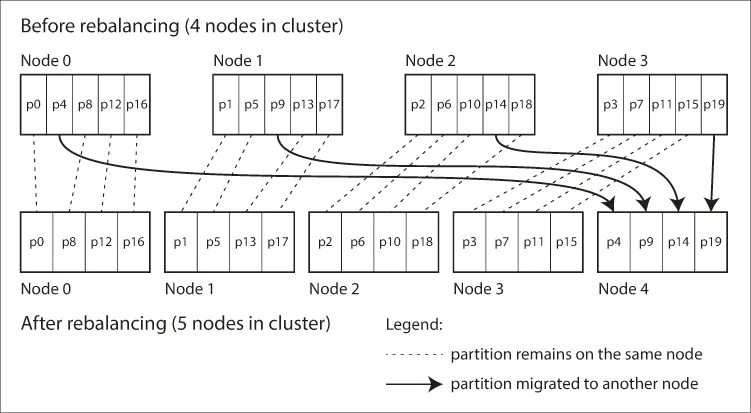
4.2. [리밸런싱 전략 2] 파티션 개수 고정
•
정의
◦
파티션의 개수 > 노드 대수
◦
각 노드에 여러 파티션 할당
◦
예)
▪
노드 10대로 구성된 클러스터, 파티션 1000개 설정, 각 노드마다 100개의 파티션 할당
•
특징
◦
클러스터에 노드 추가: 파티션이 다시 균일하게 분배 될 때까지 기존 노드에서 파티션 몇개 뺏아옴
◦
클러스터에 노드 제거: 위와 반대의 과정 실행
◦
오직 노드에 어떤 파티션이 할당되는가만 변함
▪
파티션은 노드 사이에 통째로 이동만 함
▪
파티션의 개수 및 할당된 키도 변경되지 않음.
◦
파티션 할당 변경은 즉시 반영되지 않음. 네트워크를 통해 대량의 데이터를 전송해야하므로 시간 소요
◦
데이터 전송이 진행중인 동안 읽기나 쓰기가 실행될 경우 기존에 할당된 파티션 사용
•
한계
◦
데이터베이스 초기 구축 시 파티션 개수 고정후 변경하지 않음. 파티션 개수 예측 어려움
◦
데이터셋의 크기 변동이 심할 경우, 적절한 파티션 개수 정하기 어려움
◦
각 파티션에 전체 데이터의 고정된 비율이 포함됨. 개별 파티션의 크기는 전체 데이터 크기에 비례하여 증가함
▪
파티션이 너무 클 경우, 리밸런싱 실행 및 노드 장애 복구 비용이 큼
▪
파티션이 너무 작을 경우, 오버헤드가 너무 큼
•
사용처
◦
리악, 엘라스틱 서치, 카우치베이스, 볼드모트
•
예시
4.3. [리밸런싱 전략 3] 동적 파티셔닝
•
정의
◦
키 범위 파티셔닝의 단점(파티션 경계 및 개수 고정, 특정 파티션에 쏠림 현상)을 보완하기 위해 파티션을 동적을 만드는 것
•
특징
◦
파티션 크기가 설정된 값을 넘어서면, 파티션을 두개로 쪼갬
◦
파티션의 크기가 임계값 아래로 떨어지면, 인접한 파티션과 합침
◦
키 범위 파티셔닝, 해시 파티셔닝 둘다에 적용 가능
•
장점
◦
파티션의 개수가 전체 데이터 용량에 맞춰 조정될 수 있음.
•
단점
◦
빈 데이터베이스 → 사전 정보 없음 → 시작 파티션 1개
◦
cf) 사전 분할
▪
빈 데이터베이스에 초기 파티션 집합 설정
▪
HBase, 몽고 DB에서 활용
▪
키 범위 파티셔닝의 경우, 사전 분할을 위해 어떤식으로 분할될지 미리 알아야함
4.4. [리밸런싱 전략 4] 노드 비례 파티셔닝
•
정의
◦
파티션 개수를 노드 대수에 비례하게 하는 것
◦
노드당 할당 되는 파티션 개수 고정
•
특징
◦
노드 대수 유지: 개별 파티션 크기가 데이터 셋 크기에 비례해서 증가
◦
노드 대수 증가
▪
파티션 크기 줄어듬
▪
고정된 개수의 파티션을 무작위로 선택하여 분할하여 새 노드에 할당
▪
최대한 균등하게 분할하기 위한 리밸렁싱 알고리즘 사용 (카산드라)
◦
개별 파티션 크기를 상당히 안정적으로 유지 가능
▪
데이터 용량이 클수록 데이터를 저장할 노드가 많이 필요함
▪
노드 수를 조정하여 파티션 크기 적정 유지 가능
◦
파티션 경계 무작위 선택을 위해서는 해시 기반 파티셔닝 사용해야함
•
사용처
◦
카산드라, 케타마(ketama)
4.5. 운영: 자동 리밸런싱과 수동 리밸런싱
•
완전 자동 리밸런싱
•
완전 수동 리밸런싱
•
그 중간
◦
자동으로 파티션 할당 제안
◦
반영은 관리자가 확정
◦
카우치베이스, 리악, 볼드모트
5. 요청 라우팅
•
파티션 리밸런싱 시 노드 할당되는 파티션이 바뀜
◦
어떤 IP 주소와 포트 번호로 접속??
◦
파티션 할당 변경을 잘 알아야함
→ Service Discovery 관련 이슈
5.1. 파티션 라우팅 기법
1.
클라이언트가 아무 노드 접속 → 요청 적용할 파티션이 있으면 처리, 없으면 올바른 노드로 전달하여 응답 받고 클라이언트에 응답 전달
2.
클라이언트 모든 요청을 라우팅 계층으로 전달 → 라우팅 계층에서 각 요청을 처리할 노드를 알아내고 해당 노드로 요청 전달. 라우팅 계층에서는 아무런 요청을 처리하지 않음. 파티션 인지 로드 밸런서 역할만 수행
3.
클라이언트가 파티셔닝 방법과 파티션이 어떤 노드에 할당되었는지를 알고 있게함. 중개자 없이 올바른 노드로 직접 접속 가능
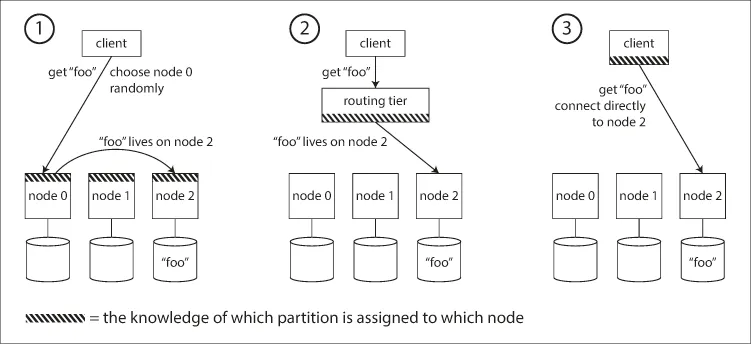
모든 경우의 핵심 문제는 라우팅 결정을 내리는 구성요소(노드, 라우팅 계층, 클라이언트)가 노드에 할당된 변경사항을 어떻게 아느냐다.
참여하는 모든 곳에서 정보가 일치해야하므로 다루기 어려움. 분산 시스템 합의 프로토콜이 있으나 제대로 구현하기 어렵고 까다로움
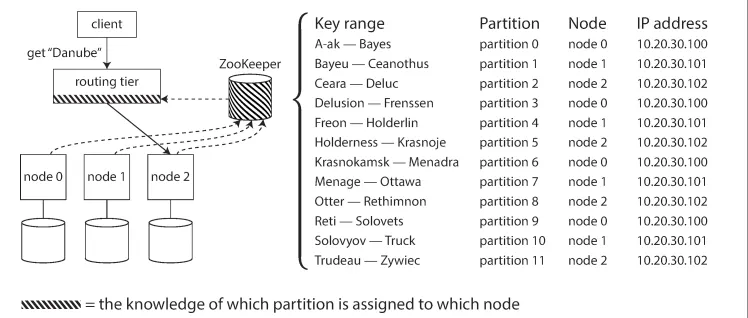
5.2. 코디네이션 서비스
•
정의
◦
분산 데이터 시스템이 클러스터 메타 데이터를 추적하기 위해 사용하는 서비스
◦
예) 주키퍼
•
특징
◦
각 노드는 주키퍼에 자신을 등록
◦
주키퍼는 파티션과 노드 사이의 신뢰성 있는 할당 정보 관리
◦
다른 구성요소들은 주키퍼에 있는 정보 구독
▪
라우팅 계층, 파티션 인지 클라이언트 등
◦
변경 발생 시 (파티션 소유자 변경, 노드 추가/삭제) 주키퍼는 라우팅 계층에 이를 알려서 라우팅 정보를 최신으로 유지하게 함
•
사용처
◦
링크드인 에스프레소: 헬릭스(클러스터 관리) → 주키퍼
◦
HBase, 카프카: 파티션 할당 추적용으로 사용
◦
몽고 DB: 설정 서버(config server), 몽고스(mongus) 데몬 - 라우팅 계층
•
다른 방법
◦
카산드라: 가십 프로토콜 (gossip protocol) - 클러스터 상태 변화를 노드 사이에 전파
◦
카우치베이스: 리밸런싱 자동 실행 X. 목시(moxi) 라우팅 계층
•
예시
6. 병렬 질의 실행
•
단일 키 / 간단한 질의에 대해서만 설명함 지금까지는…
◦
NoSQL 분산 데이터스토어에서 지원하는 접근 수준임
•
대규모 병렬 처리 (MPP, Massive Parallel Processing)
◦
복잡한 종류의 질의 지원
◦
join, filtering, grouping, aggregation
◦
MPP 질의 최적화기
▪
복잡한 질의를 여러 실행 단계와 파티션을 분해
▪
클러스터 내 서로 다른 노드를 병렬적으로 실행
7. 정리
•
파티셔닝
◦
저장하고 처리할 데이터가 너무 많아 장비 1대로 처리 불가능할 경우 사용
•
목적
◦
핫스팟(불균형, 높은 부하 노드)를 생기지 않게 하면서 데이터와 질의 부하를 여러 장비에 균일하게 분배하는 것
◦
적절한 파티셔닝 방식, 리밸런싱 방식 활용 필요
•
파티셔닝 기법
◦
키 범위 파티셔닝
▪
키가 정렬되어 있음. 개별 파티션은 특정 값 범위의 모든 키 담당
▪
범위 질의에 효율적이나, 핫스팟이 생길 가능성이 높음
◦
해시 파티셔닝
▪
각 키에 해시 함수 적용하며, 개별 파티션은 특정 범위의 해시 값 담당
▪
키 순서가 보장되지 않아 범위 질의가 비효율적이나 균일 분산 가능
▪
고정된 개수의 파티션 미리 생성 또는 동적 파티셔닝 활용 가능
•
파티셔닝과 보조 색인
◦
문서 파티셔닝 색인(지역 색인)
▪
보조 색인을 기본키와 값이 저장된 파티션에 저장
▪
쓸때는 파티션 하나만 갱신
▪
읽을 때는 모든 파티션에 걸쳐 스캐터/개더 실행
◦
용어 파티셔닝 색인(전역 색인)
▪
색인된 값을 사용하여 보조 색인을 별도로 파티셔닝
▪
쓸때는 보조 색인 여러개 갱신
▪
읽기는 단일 파티션에서 실행될 수 있음
•
파티션 라우팅 기법
스터디
1. 질문만들기
Harry
키-값 데이터 파티셔닝 종류를 비교 설명하시오
리밸런싱 전략 4가지에 대해 설명하시오
서비스 디스커버리란?
코디네이션 서비스의 역할은?
Matthew
노드와 파티셔닝을 어떻게 이해해야 하는가? → 위 질문에서 처리, 진행중
문서/용어 보조 색인 파티셔닝 색인이 적합한 경우는 각각 언제일까?
전역 색인은 쓰기가 느리고 복잡한 이유가 무엇일까?
2. 핵심 질문에 답하기
3. 책 같이 살펴보기
•
(212 P) 동적 파티셔닝에서 한개의 파티션이 n개로 나눠지는 경우 이를 어떻게 추적 할까?