내용 정리
0. Intro
•
저장소 엔진 종류
◦
로그 구조(log-structured) 계열 저장소 엔진
◦
페이지 지향(page-oriented) 계열 저장소 엔진
•
로그
◦
애플리케이션 로그의 개념보다 더 일반적인 개념
◦
연속된 추가 전용 레코드
•
색인
◦
어떤 부가적인 메타데이터를 유지하는 것
◦
기본 데이터에서 파생된 추가적인 구조
1. 해시 색인
1.1. 정의
•
키를 데이터 파일의 바이트 오프셋에 매핑하여 인메모리 해시맵에 유지
•
파일에 새로운 키-값 쌍 추가할때마다 데이터 오프셋 반영을 위해 해시맵 갱신 필요
•
비트캐스크 사용 방식
◦
해시맵을 전부 메모리에 유지 (RAM에 모든 키 저장)
◦
고성능 읽기, 쓰기
1.2. 컴팩션과 세그먼트 병합
•
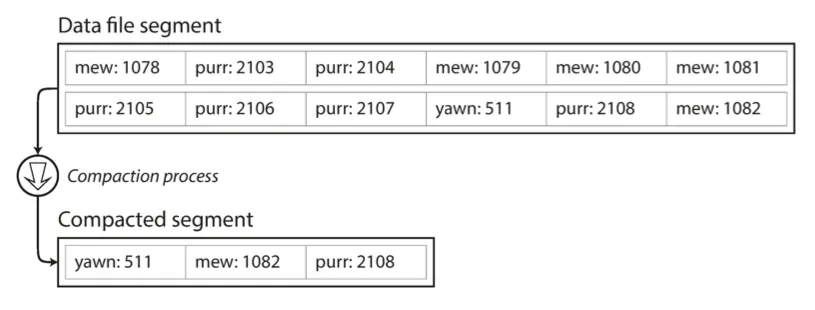
로그에 중복된 키 제거 & 각 키의 최신 갱신 값만 유지하는 것
•
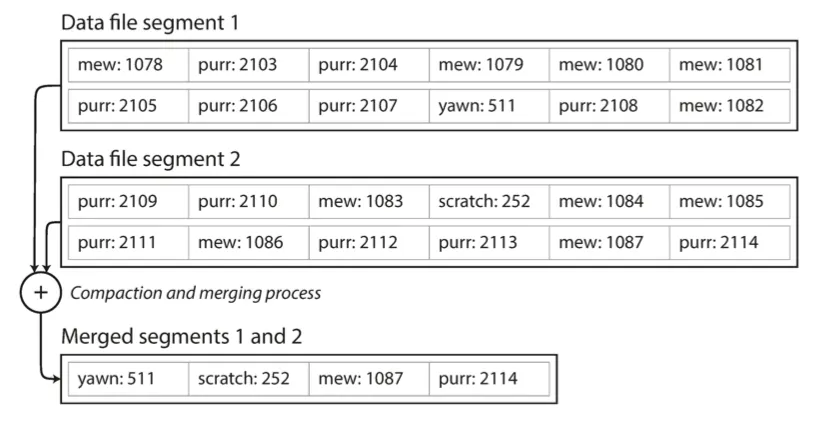
컴팩션은 세그먼트를 작게 만들기때문에 컴팩션 수행 시 동시에 여러 세그먼트 병합 가능
◦
세그먼트 병합과 컴팩션은 백그라운드 스레드로 수행
◦
그 동안 이전 세그먼트 파일에 읽기/쓰기 요청 처리
◦
병합 및 컴팩션 완료 후, 새롭게 병합된 세그먼트로 전환
1.3. 실제 구현 고려사항
•
파일 형식
◦
바이너리 형식 (CSV x)
•
레코드 삭제
◦
데이터 파일에 특수한 삭제 레코드를 추가 필요
•
고장 복구
◦
데이터베이스 재시작 시 인메모리 해시맵 손실
◦
전체 세그먼트 파일을 모두 읽고 각 키에 대한 최신 값의 오프셋을 확인하여 세그먼트 해시맵 복원
▪
시간이 상당히 소요됨
◦
비트캐스크는 스냅샷을 디스크 저장
•
부분적 레코드 쓰기
◦
로그에 레코드 추가중 죽을 수 있음
◦
비트캐스크
▪
체크섬
•
동시성 제어
◦
하나의 쓰기 스레드 사용
◦
데이터 파일 세그먼트는 추가전용이거나 불변이므로 다중 스레드로 동시에 읽기 가능
cf) 추가 전용 로그
•
추가와 세그먼트 병합은 순차적인 쓰기 작업이므로 무작위 쓰기보다 빠름
•
세그먼트 파일이 추가전용/불변이면 동시성과 고장 복구가 간단
cf) 제한 사항
•
메모리에 저장해야하므로 키가 너무 많으면 문제가 됨
•
범위 질의에 비효율적
2. SS 테이블
2.1. 정의
•
로그 구조화 저장소 세그먼트 내 키-값 쌍을 키로 정렬한 것
•
키로 정렬된 형식
◦
정렬된 문자열 테이블 (Sorted String Table) 또는 SS 테이블 이라고 함
•
세그먼트를 병합하고 각키의 최신값만 유지
◦
병합정렬 방식과 유사
2.2. 프로세스 및 특징
•
프로세스
1.
입력파일을 함께 읽고 각 파일의 첫번째 키를 봄 (정렬된 순서에 따라)
2.
가장 낮은 키를 출력 파일로 복사
3.
이 과정에서 새로운 병합 세그먼트 파일이 생성 (키 정렬 포함)

•
특징
◦
다중 세그먼트가 동일한 키를 포함한 경우 가장 최근 세그먼트의 값만 유지
◦
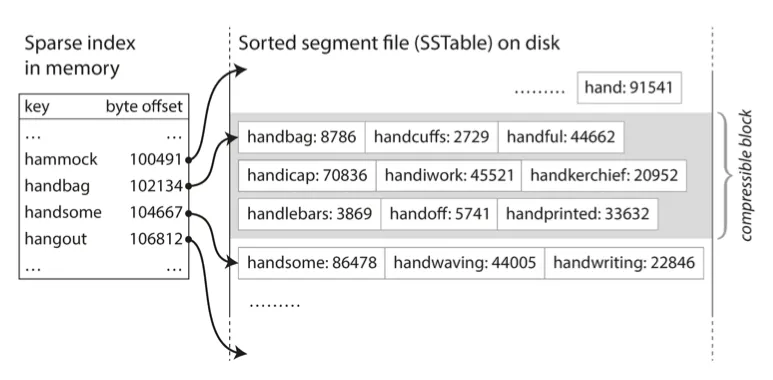
파일의 특정 키를 찾기위해 메모리에 모든 키 색인 유지 불필요
◦
세그먼트 파일에 키의 정확한 오프셋을 모르더라도 다른 키의 오프셋을 통해 탐색 가능
▪
예) handiwork는 handbag과 handsome 사이에 있음을 알 수 있음
인메모리 색인을 가진 SS테이블
◦
일부 키에 대한 오프셋을 알려주기 위한 인메모리 색인은 여전히 필요. 그러나 색인 내용은 희소할 수 있음
▪
세그먼트 파일 내 수 KB당 키 1개면 충분
◦
압축 블록
▪
읽기 요청은 요청 범위 내에서 여러 키-값 쌍으로 스캔 해야함
▪
따라서 해당 레코드들을 블록으로 그룹화하고 디스크에 쓰기전에 압축함 (위 그림의 음영 영역)
▪
희소 인메모리 색인의 각 항목은 압축된 블록의 시작을 가리키게됨.
▪
디스크 공간 절약 + I/O 대역폭 사용 줄임
3. LSM 트리
3.1. 정의
•
로그 구조화 병합 트리 (Log-Structured Merge Tree)
•
임의 순서로 키 삽입 + 정렬된 순서로 키 읽기 위한 알고리즘
•
LSM 저장소 엔진
◦
정렬된 파일 병합과 컴팩션 원리를 기반으로 하는 저장소 엔진
3.2. 프로세스
•
쓰기가 들어오면 인메모리 균형 트리(멤테이블) 데이터구조에 추가
•
멤테이블이 보통 수 메가바이트 정도 임계값보다 커지면 SS테이블 파일로 디스크에 기록
◦
트리가 이미 정렬된 키-값 쌍을 유지하므로 효율적으로 수행 가능
◦
새로운 SS 테이블 파일은 DB의 가장 최신 세그먼트가 됨
◦
SS 테이블을 디스크에 기록하는 동안 쓰기는 새로운 멤테이블 인스턴스에 기록
•
읽기 요청
◦
먼저 멤테이블에서 키를 찾음
◦
그다음 디스크 상의 가장 최신 세그먼트에서 찾음
◦
그다음 두번째 오래된 세그먼트….
•
병합과 컴패션 과정을 백그라운드에서 수행
3.3. 성능 최적화
•
LSM 알고리즘은 데이터베이스에 존재하지 않는 키 탐색시 느림
◦
멤 테이블 → 세그먼트 탐색 (첫번째 → 두번째 → …. 가장 오래된 세그먼트)
•
블룸 필터 (Bloom filter)
◦
집합 내용을 근사한 메모리 효율적 데이터 구조
◦
키가 데이터베이스에 존재하지 않음을 알려줌
•
SS 테이블 압축 및 병합 순서와 시기 결정을 위한 전략들
◦
크기 계층(size-tiered)
▪
상대적으로 좀더 새롭고 작은 SS 테이블을 상대적으로 오래됐고 큰 SS 테이블에 연이어 병합
◦
레벨 컴팩션(leveled compaction)
▪
키 범위를 더 작은 SS 테이블로 나눔
▪
오래된 데이터는 개별 레벨로 이동
▪
점진적으로 컴팩션을 진행해 디스크 공간을 덜 사용
•
LSM 트리
◦
기본 개념
▪
백그라운드에서 연쇄적으로 SS테이블을 지속적으로 병합
◦
데이터가 정렬된 순서로 저장되어있으므로 범위 질의에 효율적
◦
접근 법의 디스크 쓰기는 순차적
▪
매우 높은 쓰기 처리량 보장 가능
스터디
Harry
컴팩션과 세그먼트 병합의 프로세스를 서술하시오
LSM트리와 SS 테이블의 차이와 특징을 서술하시오
로그 구조화 저장소 엔진란?
Matthew
색인과 쓰기 속도와의 관계는 어떠한가
LSM 트리의 기본 개념
해시맵전략(해시테이블) 색인이 효율적이지 않은 경우는 언제인가